 Druid Queries - Data Schema
Druid Queries - Data Schema
February 12, 2021
February 12, 2021
This is part one of a blog post series about Druid Queries.
To get started, we’re going to run a local Druid cluster using Docker and Docker Compose. Let’s start by grabbing the latest docker-compose.yml and environment files from the Druid source code.
$ cd ~/src/blog/druid-queries
$ wget "https://raw.githubusercontent.com/apache/druid/master/distribution/docker/docker-compose.yml"
$ wget "https://raw.githubusercontent.com/apache/druid/master/distribution/docker/environment"
$ docker-compose up
Once the cluster has fully launched, you can view the Druid unified console at http://localhost:8888.
For this tutorial, we’re going to use the open MovieLens 25M Dataset which contains 25M movie ratings, 1M tags, 62,000 movies, and 162,000 users. Additionally, since this download is over HTTP, we’re also going to grab the md5 file so we can compare checksums to validate our payload is correct.
$ wget "http://files.grouplens.org/datasets/movielens/ml-25m.zip"
$ wget "http://files.grouplens.org/datasets/movielens/ml-25m.zip.md5"
$ md5 ml-25m.zip && cat ml-25m.zip.md5
MD5 (ml-25m.zip) = 6b51fb2759a8657d3bfcbfc42b592ada
6b51fb2759a8657d3bfcbfc42b592ada ml-25m.zip
$ unzip ml-25m.zip
Archive: ml-25m.zip
creating: ml-25m/
inflating: ml-25m/tags.csv
inflating: ml-25m/links.csv
inflating: ml-25m/README.txt
inflating: ml-25m/ratings.csv
inflating: ml-25m/genome-tags.csv
inflating: ml-25m/genome-scores.csv
inflating: ml-25m/movies.csv
MD5 hashes 6b51fb2759a8657d3bfcbfc42b592ada match, so we’re safe to continue.
Let’s examine a few records from movies.csv and ratings.csv to get an idea of what our data contains.
$ cd ~/src/blog/druid-queries/ml-25m
$ head -n5 movies.csv
movieId,title,genres
1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy
2,Jumanji (1995),Adventure|Children|Fantasy
3,Grumpier Old Men (1995),Comedy|Romance
4,Waiting to Exhale (1995),Comedy|Drama|Romance
$ head -n5 ratings.csv
userId,movieId,rating,timestamp
1,296,5.0,1147880044
1,306,3.5,1147868817
1,307,5.0,1147868828
1,665,5.0,1147878820
It appears that movies.csv contains static information about a movie and ratings.csv contains information about individual users giving a movie a star rating at a specific time.
Druid’s primary partition dimension is on time, which we have in our timestamp field, which appears to be unix epoch in seconds.
Users are uniquely identified by the userId field but we don’t have anymore information on them.
The star rating is a float value but I’m not sure if it’s a zero based scale, up to 10, etc. Let’s see if xsv can help.
$ xsv stats --select '3' ratings.csv
field,type,sum,min,max,min_length,max_length,mean,stddev
rating,Float,88346697,0.5,5,3,3,3.533854451353244,1.0607439399275103
The min rating value is 0.5 and the max is 5 so it appears to be a 0-5 scale, where I assume 5 is the best.
The default should be enough data for most of our queries except we don’t have a unique identifier for each individual rating event. Since this is a static dataset and we assume it has been somewhat cleaned, we’ll just add a column that maps to the CSV row number and use that as a ratings id.
Let’s write a quick python script to do that and save this as add-rating-id.py.
import fileinput
import sys
row_number = -1
for line in fileinput.input():
if row_number < 0:
line = 'ratingId,' + line
sys.stdout.write(line)
sys.stdout.flush()
else:
line = '{},'.format(row_number) + line
sys.stdout.write(line)
sys.stdout.flush()
row_number += 1
With this script and xsv, we can join our csv files and add our new rating id column.
Note: This joined csv file is going to be ~2GB, so make sure you have the available disk space.
$ xsv join --no-case movieId movies.csv movieId ratings.csv | xsv select '!5' | python add-rating-id.py > ratings-joined.csv
$ ls -lah ratings-joined.csv
-rw-r--r-- 1 hawker staff 1.9G Nov 24 10:31 ratings-joined.csv
These commands are doing the following:
movies.csv and ratings.csv files together on the movieId column.movieId column from the output. select '!5' means select all columns excluding the 5th.ratingId column to the csv and add a zero based id value to each entry that represents the row number.ratings-joined.csvThe joined dataset looks as follows:
$ head -n5 ratings-joined.csv
ratingId,movieId,title,genres,userId,rating,timestamp
0,1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy,2,3.5,1141415820
1,1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy,3,4.0,1439472215
2,1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy,4,3.0,1573944252
3,1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy,5,4.0,858625949
Druid datasources are pretty much standard database tables. They have some additional properties which you can read about, for our purposes, just think of them as a table.
Let’s define a datasource that matches the structure of our ratings-joined.csv file so we can ingest it. There’s a lot of here but don’t worry, we’ll go over it section by section.
{
"type" : "index",
"spec" : {
"dataSchema" : {
"dataSource" : "ratings",
"timestampSpec": {
"column": "timestamp",
"format": "posix"
},
"dimensionsSpec" : {
"dimensions" : [
"genres",
"title"
]
},
"metricsSpec" : [
{
"name": "count",
"type": "count"
},
{
"fieldName": "rating",
"name": "rating_min",
"type": "floatMin"
},
{
"fieldName": "rating",
"name": "rating_max",
"type": "floatMax"
},
{
"fieldName": "rating",
"name": "rating_sum",
"type": "floatSum"
},
{
"fieldName": "rating_id",
"name": "rating_id_sketch",
"type": "thetaSketch"
},
{
"fieldName" : "rating",
"name" : "rating_sketch",
"type" : "quantilesDoublesSketch"
},
{
"fieldName": "user_id",
"name": "user_id_sketch",
"type": "thetaSketch"
}
],
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "year",
"queryGranularity": "day",
"intervals": [
"2019-01-01/2020-01-01"
]
}
},
"ioConfig" : {
"type" : "index",
"listDelimiter": "|",
"inputSource" : {
"type" : "local",
"baseDir" : "/opt/data/datasets/",
"filter" : "ratings-joined.csv"
},
"inputFormat" : {
"type": "csv",
"columns": [
"rating_id",
"movie_id",
"title",
"genres",
"user_id",
"rating",
"timestamp"
],
"findColumnsFromHeader": false,
"skipHeaderRows": 1
},
"appendToExisting" : false
}
}
}
There’s a lot here, so let’s break it down. 1
The timestampSpec defines the time dimension of our data, which is the timestamp field as an epoch (seconds) integer. Druid automatically partitions and sorts data by time and creates its segment files using these time values.
The dimensionSpec defines columns that are stored, unmodified. These can be used for the usual query/sort/filter patterns one would expect.
The metricsSpec defines columns that are aggregated at ingestion time. Druid will rollup multiple ingested rows into one and retain summary information about it. This is one of the approaches to compression that greatly speed up queries and save disk space.
We define two important metrics here of type thetaSketch and quantilesDoublesSketch. These fields are going to be the main drivers for our future query examples and we’ll cover them in more depth in future posts.
The granularitySpec defines how rollups are performed and data is stored. The segmentGranularity defines the time bounds for individual segment files. For the best performance, you’re looking for segment files around ~500mb. 2 In our case, we’re creating one segment file for each year.
The queryGranularity value defines the smallest interval of time we can filter/group our data. By setting this value to day, it means we cannot find individual ratings by hour, minute, or second. Changing this value depends on your use cases, but the larger the queryGranularity, the better query performance/data savings we’ll receive.
The intervals value lets us define a time range for “valid” data that should be ingested. If undefined, Druid will detect these time ranges based on the data being ingested but this can increase your memory usage requirements.
The ioConfig defines the data we’re ingesting, which is just a single .csv file. Be sure to note that we’re setting listDelimiter to | so the genres column is properly split and stored as an array. We are also defining the columns from the CSV. We can let Druid auto-discover these values, but I’ve decided to define them myself so we can enforce snake case naming conventions.
Note: If you’re running a small cluster with docker-compose, it’s unlikely you have enough available RAM to ingest the file in one go. That’s OK. We’re going to outline the process for creating separate ingestion tasks for each year in the dataset.
Save the datasource JSON document defined above into ratings-datasource.json. From there, we’re going to want to modify the intervals value of our granularitySpec for each individual year within the dataset.
According to the MovieLens README, it should contain records from 1995 to 2019, so we’ll start with 1995.
"intervals": [
"1995-01-01/1996-01-01"
]
Now, we can schedule a Druid index task with a simple curl command. This will consume our CSV file and create data segments for all data found in 1995. Since we’re also using a segmentGranuarlity of year, we’ll only create one segment file for running this task and it will only contain data from 1995.
curl -XPOST -H 'Content-type: application/json' -d @ratings-datasource.json http://localhost:8081/druid/indexer/v1/task

You should be able to see your active ingestion task in the console and once completed, you should see a single segment for 1995 listed in the segments view as well.

Now, repeat this process for all of the years in the dataset. Once you’re done, you should have segments for each year from 1995 through 2019 and have a segment listing something like this.
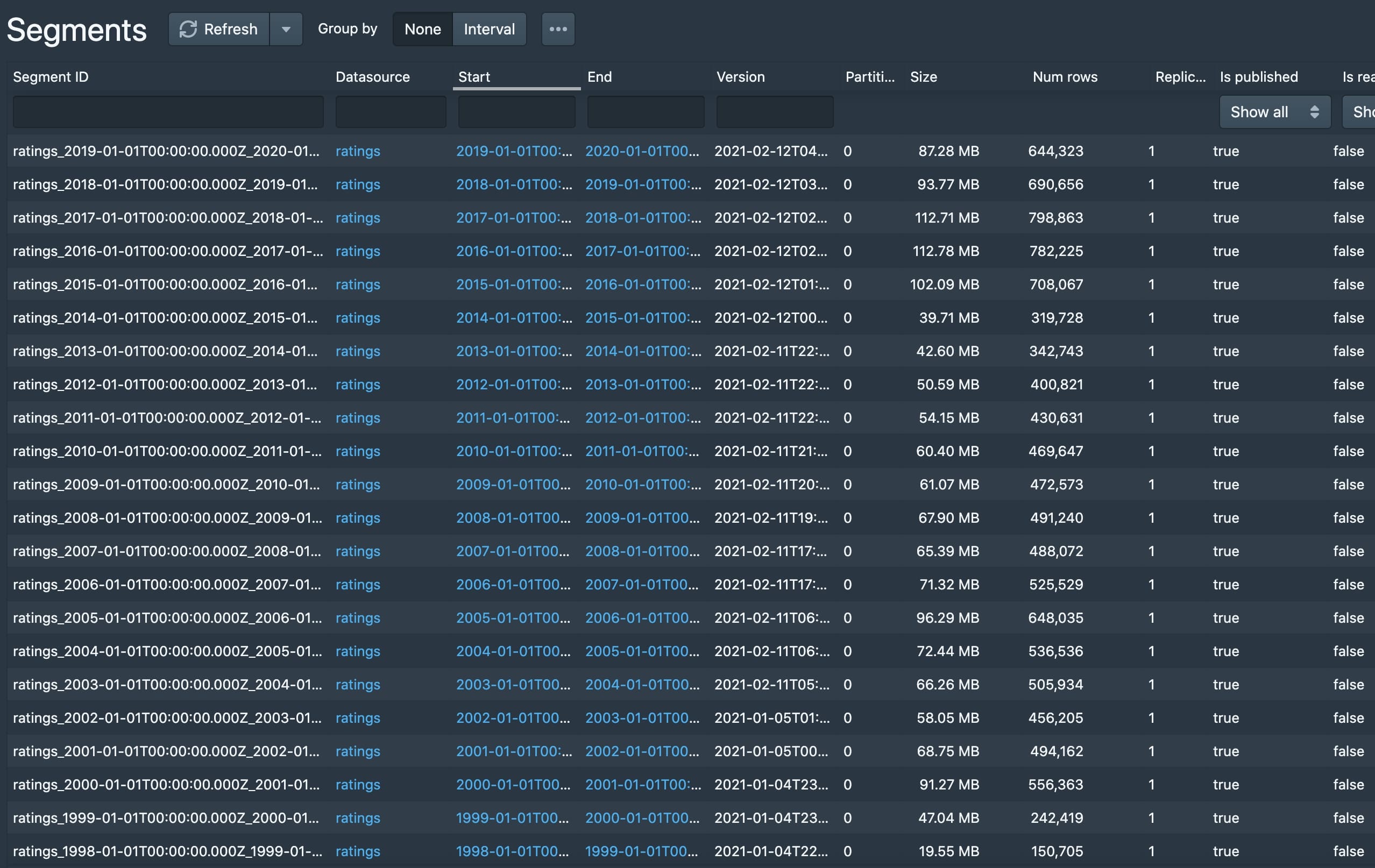
Now that we’re done ingesting all of the MovieLens data, let’s make some simple queries to validate everything is working as expected. Let’s open up the query dashboard in the Druid unified console at http://localhost:8888/unified-console.html#query.
We can see the total number of records ingested, which aligns to the ~25 million we expect.
select sum("count") from ratings
25000095
We can count individual records stored after rollup, which is about 1/2 of the total ingested.
select count(*) from ratings
11484733
Whew, that was quite a bit. If you’ve made it this far, I salute you.

In the next post, Active Users, we’ll get into the actual queries and dive into tracking DAU, WAU, MAU over time. Stay tuned!
Druid data modeling https://druid.apache.org/docs/latest/ingestion/index.html#druids-data-model. ↩
Optimal segment file sizes https://druid.apache.org/docs/latest/design/segments.html ↩